
[Paper Review] Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback (EMNLP 2023)
Published:
RLHF-LM으로 자신감 점수를 생성하기
Abstract
신뢰할 수 있는 real-world 예측 모델은 well-calibrated confidence 점수를 생성한다. 예측이 정답과 동일하면서 예측에 대한 likelihood가 높을 때 confidence가 높다고 한다. 최근 연구에 따르면 large language model (LLM)의 unsupervised pretraining을 통해 conditional probability가 well-calibrated 되었다고 한다. 하지만, human feedback을 통해 학습하는 RLHF-LM이 생성하는 conditional probability는 잘 calibrate하지 못한다. 해당 논문에서는 출력 토큰의 verbalized-confidence가 모델의 conditional probability보다 잘 calibrate하는 것을 보인다.
Introduction
실제 시스템은 에러를 생성한다. 시스템이 well-calibrated 신뢰도 추정 값을 제공한다면, 모델이 필연적으로 생성하는 오류를 어느 정도 완화할 수 있다. 시스템이 가장 confidence 없이 출력한 응답이 가장 정답이 아닐 확률이 높다는 가정에서 출발한다. 최근 연구에 따르면 LLM이 주어진 입력에 대해 가장 가능성이 높은 출력이 생성하도록 maximum likelihood가 사용되기 때문에 선호하는 응답을 출력하도록 생성하는 RLHF-LM의 경우 well-calibrated 예측 능력을 희생한다고 한다. 따라서, 해당 논문에서는 모델 출력의 confidence을 측정하는 여러 방법들을 비교한다. 해당 논문에서는 RLHF-LM이 fine-tuning 없이 스스로 verbalized probability를 생성할 수 있다는 것을 발견했다. 또한 confidence score를 평가하기 전에 모델에게 여러 응답 선택권을 주는 것이 verbalized probabilities의 calibration을 향상시킬 수 있다는 것을 보인다. 따라서, 해당 논문에서는 verbalized 확률을 추출할 수 있는 여러 프롬프트를 제공하며, 다른 calibration 측정 방법들과 비교한다.
Evaluating Clibration in RLHF-LMs
Metrics
Calibration 측정을 위해서 해당 논문에서는 ECE, Brier score, AUC를 측정한다. ECE는 모델의 출력의 confidence를 bin으로 나누어 각 bin에 대해 평균 accuracy를 측정한다. ECE는 각 bin 별 평균 정확도와 confidence간의 means squared error로 계산한다. 추가적으로 temperature scaling을 더한 ECE-t도 사용한다. 다만 ECE의 경우 bin confidence의 분별 능력을 평가하지 못하기 때문에 한계가 존재한다. 예를 들어, 만약 binary classification을 하면, 시스템이 무작위로 추측하고 매번 50%의 confidence를 출력한다면 완벽한 ECE 점수를 얻게된다. 따라서, confidence와 레이블 간의 mean squared error를 평가하는 Brier score와 selective classifcation에서 사용하는 selective accuracy와 coverage를 측정하는 AUC를 추가적으로 사용하여 평가한다.
Method

Confidence score를 측정하는 가장 간단한 방법으로는 conditional probability를 측정하는 Label prob. 방법이 있다. 많은 RLHF-LM이 closed-source이기에 per-token probability를 제공하지 않는다. 따라서, n=10의 sample을 생성하여 per-token probability를 측정하였다. 비슷하게 ‘Is True’ prob.의 경우 모델이 ‘True’로 출력한 비율을 통해 probability를 측정하였다.

다른 방법으로 verbalization을 통해 모델이 token space에서 numerical probability 혹은 linguistic expression을 생성하는 방법에 대해 집중한다. 먼저 Verb. 1S top-k의 경우 모델이 $k$개의 guess를 생성하여 각 guess가 단일 응답과 정확할 확률을 생성하도록 한다. 그 후에 가장 높은 확률을 가지는 prediction을 사용한다.

두 번째 방법으로 Verb. 2S top-k의 경우 1-stage에서 응답만을 생성하도록 하고, 그 후에 각 정답과의 일치하는 지 probability를 생성하도록 한다. Verb. 2S CoT의 경우 단일 응답을 생성하기 전에 chain-of-thought을 주고 그 후에 해당 응답에 대해 probability를 측정하는 방법이다.

Ling. 1S-human은 numerical probability가 아니라 linguistic probability를 측정하는 방법이다. 모델에 언어적 표현 리스트를 줘서 그 중 표현을 선택하는 방식이다. 각 linguistic likelihood expression은 소셜 미디어의 123개의 사람의 응답에 매핑된다. Ling. 1S-opt.는 각 표현의 likelihood의 평균 정확도를 사용하는 optimized 값을 이용하는데, 최소 질문의 $1/N$만큼 응답하지 않은 표현은 human probability를 대신 사용한다.
Result
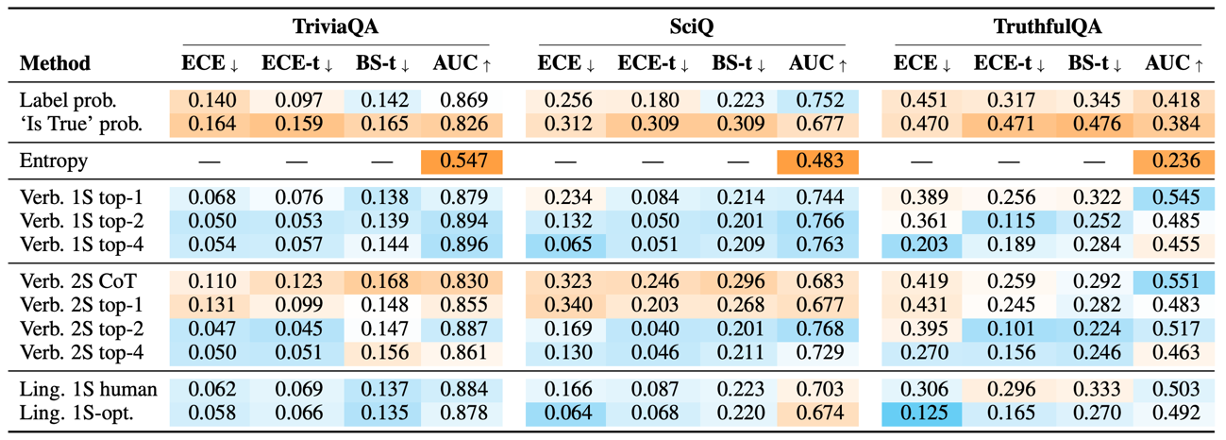
gpt-3.5-turbo (ChatGPT)를 사용한 결과이다.
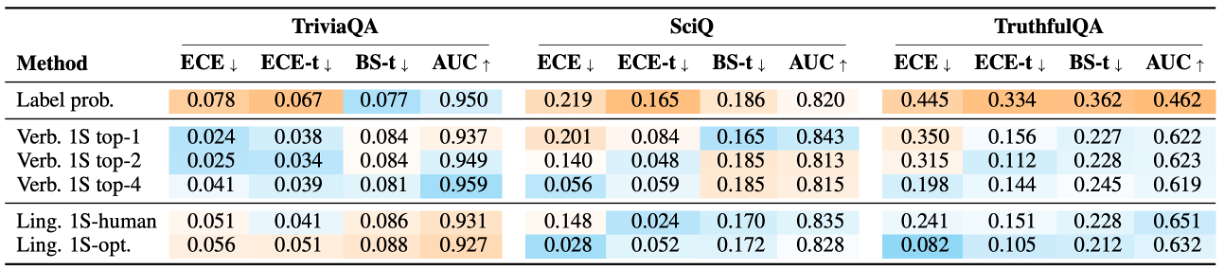
gpt-4를 사용한 결과이다.
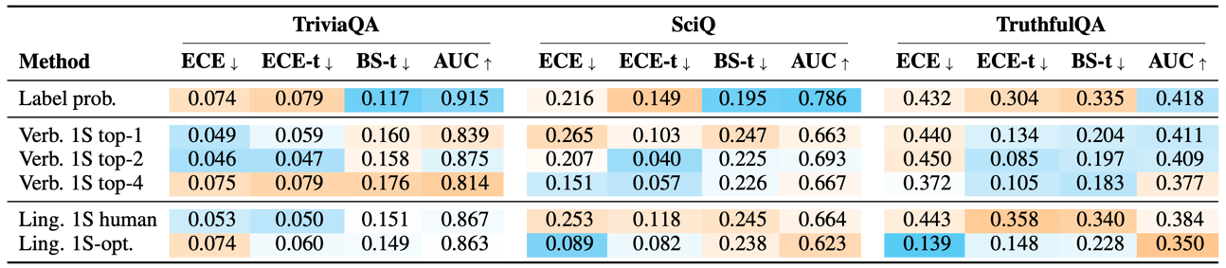
Claude-1을 사용한 결과이다. Log probability는 gpt-3.5-turbo보다 좋지만 verbalized probability는 더 낮다.
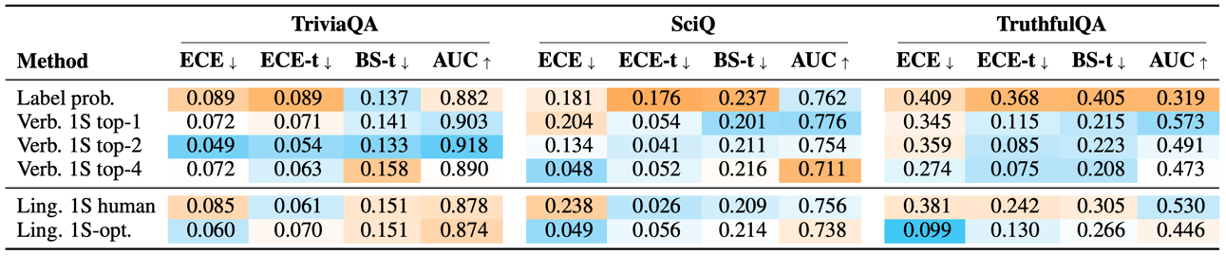
Claude-2를 사용한 결과이다. TrustfulQA에서 verbalized probability가 특히 좋은 성능을 보인다.
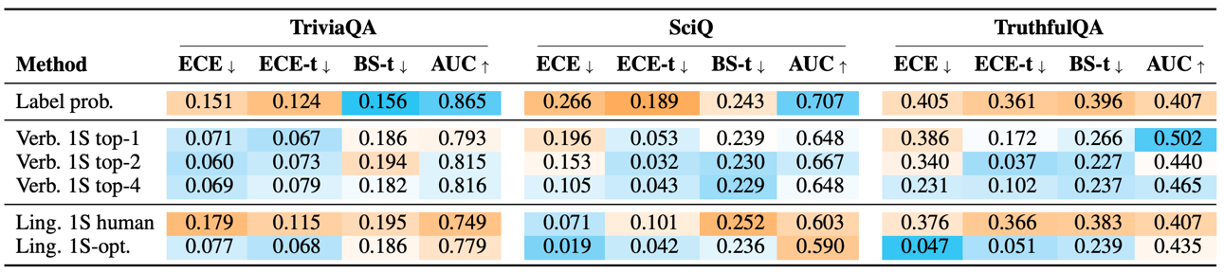
Llama2-70B-Chat을 사용한 결과이다. Verbalized probability가 대부분 conditional probability보다 높지만 GPT나 Claude에 비해 낮은 성능을 보인다.
따라서, 해당 다양한 결과들을 통해 추론할 수 있는 분석은 다음과 같다.
- 결과적으로 거대한 RLHF-LM은 conditional probability보다 더 좋은 calibrated 점수를 직접 verbalize할 수 있다.
- Verbailize probability를 직접 생성하는 것보다 여러 hypothesis를 생성하고 평가하는 것이 calibration의 효과를 증가시킨다.
- Language model은 unceratinty를 word로 표현하는 것보다 numerical probability로 더 잘 표현한다는 것을 발견했다. 숫자를 잘 표현하지 못하는 것으로 알려진 LLM이기에 이 결과는 흥미롭다.
- Chain-of-thought 프롬프팅이 verbalized calibration의 성능을 향상시키지 못한다.
- GPT 시리즈가 Claude나 Llama2보다 calibration 성능이 높다.
Conclusion
해당 논문에서는 RLHF-LM의 calibration을 제대로 평가하기 위해 verbalized probability를 제안한다. 결과적으로 GPT 시리즈가 가장 잘 verbalized probability를 생성하였다. 아이디어는 단순하지만, 창의적인 방법을 통해 모델의 calibration을 평가한 것이 굉장히 흥미롭다. 해당 논문에서는 short-form question answering에 적용을 하였는데, 요약 태스크처럼 long-form 태스크에도 적용해볼 필요가 있을 것 같다.